

Die freie Redakteurin Sonja Koesling sprach für unser White Paper „Von Gerätedaten zu smarten Informationen – mehr Kontext für das Engineering“ mit Dr. Max Hoffmann, Leiter Digitalisierung beim Fraunhofer-Institut für Produktionstechnologie (IPT).

Dr. Max Hoffmann beschäftigt sich beim IPT mit der Frage, wie aus Industrial Big Data smarte Informationen werden. Seine Doktorarbeit konzentrierte sich darauf, intelligente Fertigungsagenten in die Lage zu versetzen, Produktionsprozesse durch KI-gesteuerte Verhandlungs- und Planungsalgorithmen autonom zu optimieren.
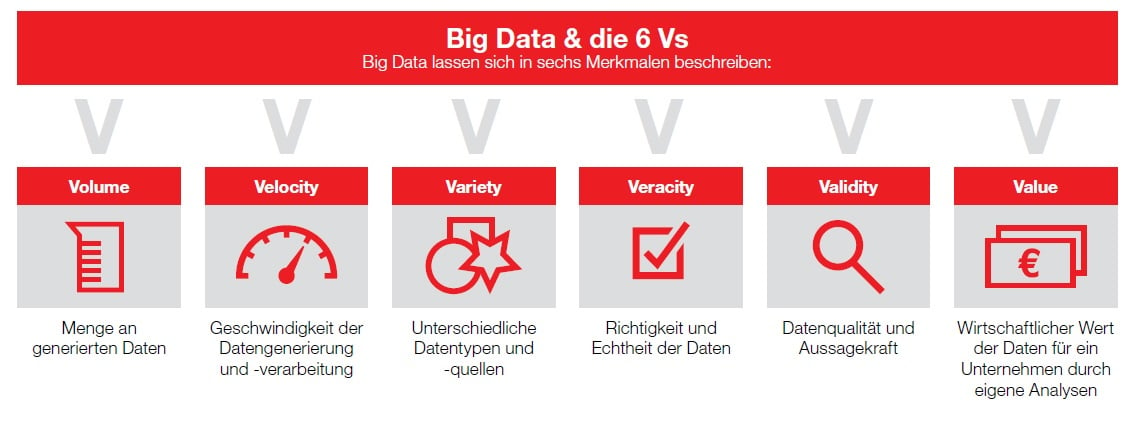
Das Öl raffinieren: Die 6 Vs der Big Data
Daten sind das neue Öl. Als Rohstoff ist es wertvoll. Doch wenn es nicht raffiniert ist, lässt sich mit ihm wenig Brauchbares anfangen. Es muss erst in Benzin, Kunststoff oder Ähnliches umgewandelt werden, um einen Nutzen zu erzeugen. Genau so verhält es sich mit Daten: Nur wer sie strukturiert und in einen Kontext setzt, kann aus Big Data smarte Informationen gewinnen. Big Data heißen die großen Datenmengen, die sehr divers sind und rasch anwachsen. Ihr Charakter folgt den drei grundlegenden Vs: „Volume“ definiert die enormen Mengen. Ihre Vorkommen sind so komplex, dass sie sich mit herkömmlichen Methoden nicht mehr analysieren lassen. „Velocity“ bezeichnet die Geschwindigkeit, mit der die Daten generiert und weiterverarbeitet werden. „Variety“ bezieht sich auf die Vielfalt an Datentypen und deren Quellen. Mit den weiterführenden Vs „Veracity“, „Validity“ und „Value“ ergeben sie die sechs Vs als entscheidende Merkmale von Big Data.
 „Indem wir beispielsweise Twitter, Facebook und Co. nutzen, generieren wir Text-, Bild- und Videodateien. Diese ‚traditionellen Big Data‘ sind in der Regel menschengemacht und klassischerweise unstrukturiert“, erklärt Dr. Max Hoffmann. Dazu zählen auch Abfragen über Suchmaschinen, Bestellungen über Online-Shops, Bewertungen von Restaurants, Händlern und Produkten auf diversen Portalen, das Teilen von Fotos und Textnachrichten über Social-Media-Dienste, Musikvorschläge anhand bisher gehörter Songs… Seit 2005 hat sich die Anzahl digitaler Informationen alle zwei Jahre verdoppelt. Studien prognostizieren, dass im Jahr 2025 weltweit rund 175 Zettabyte an Daten erzeugt werden. Der Anteil an unstrukturierten Daten liegt laut Experten bei rund 80 Prozent.
„Indem wir beispielsweise Twitter, Facebook und Co. nutzen, generieren wir Text-, Bild- und Videodateien. Diese ‚traditionellen Big Data‘ sind in der Regel menschengemacht und klassischerweise unstrukturiert“, erklärt Dr. Max Hoffmann. Dazu zählen auch Abfragen über Suchmaschinen, Bestellungen über Online-Shops, Bewertungen von Restaurants, Händlern und Produkten auf diversen Portalen, das Teilen von Fotos und Textnachrichten über Social-Media-Dienste, Musikvorschläge anhand bisher gehörter Songs… Seit 2005 hat sich die Anzahl digitaler Informationen alle zwei Jahre verdoppelt. Studien prognostizieren, dass im Jahr 2025 weltweit rund 175 Zettabyte an Daten erzeugt werden. Der Anteil an unstrukturierten Daten liegt laut Experten bei rund 80 Prozent.
Herausforderung für die Industrie: neue Strukturen für alte Systeme
„Im Gegensatz dazu sind ‚Industrial Big Data‘ maschinengemacht und in irgendeiner Weise strukturiert“, so Hoffmann. Die Herausforderung bei diesen Daten besteht eher darin, dass diese Strukturen nicht einheitlich, sondern über die Jahre verschieden gewachsen sind. Denn im Zuge der Digitalisierung hat sich das Gros der Industrieunternehmen auf die kontinuierliche Optimierung von Kernprozessen fokussiert. Das hat Insellösungen und verstreute Datenbestände hervorgerufen. So stehen in einer Fabrikhalle Maschinen, von denen manche bereits das 30. Lebensjahr erreicht haben, andere hingegen erst fünf Jahre im Einsatz sind. Ihr unterschiedliches Baujahr macht sich in der Informationstechnologie bemerkbar, mit der sie ausgestattet sind und die zum Zeitpunkt ihrer Entstehung dem jeweiligen Stand der Technik entsprach. „Da ist eine Systemlandschaft herangewachsen, die sich aus unterschiedlichen Technologien verschiedenster Generationen zusammensetzt“, berichtet Hoffmann. Wer aus Industrial Big Data Mehrwert generieren möchte, muss sich mit diesen sogenannten „Brown Fields“ auseinandersetzen. „Das bedeutet, dass ich diese, über die Jahre gewachsenen Systeme irgendwie strukturieren muss“, sagt Hoffmann.
Der Kontext definiert die Datenqualität
Das reine Datum reicht nicht aus: „Werfe ich eine Zahl in den Raum, dann ist das ein schlichtes Datum. Denn mit einem Wert wie ‚23,5‘ kann keiner etwas
anfangen“, sagt Hoffmann. „Füge ich jedoch hinzu, dass dies die Temperatur ist, die heute bei mir im Büro herrscht, habe ich das Datum mit einer Einheit
versehen und es um eine Orts- sowie Zeitangabe ergänzt.“ Für das Gegenüber ergibt das Datum nun einen Sinn. Es kann die Information aufnehmen und
verarbeiten. „Ich muss Daten also in einen Kontext setzen, um ihren Inhalt verstehen zu können“, erklärt Hoffmann. Ohne Kontext sind Daten wertlos. Erst der Kontext mit domänenspezifischen Metainformationen verwandelt Industrial Big Data in smarte Informationen...
Lesetipp: "Von Gerätedaten zu smarten Informationen"
Als Verfechter konsistenter Datenmodelle – so kennen Sie Eplan. Denn je durchgängiger Sie mit den zur Verfügung stehenden Daten arbeiten können, desto effektiver wird Ihre Schaltschrankplanung sein. Dabei bildet dieser Fakt nur einen Baustein Ihrer Unternehmung. Mit unserem neuen White Paper möchten wir dieses Puzzleteil in einen größeren Kontext setzen und Ihnen zeigen, warum Datenqualität und Datentiefe mehr sind als akkurates Engineering.
Kommentar verfassen